FL
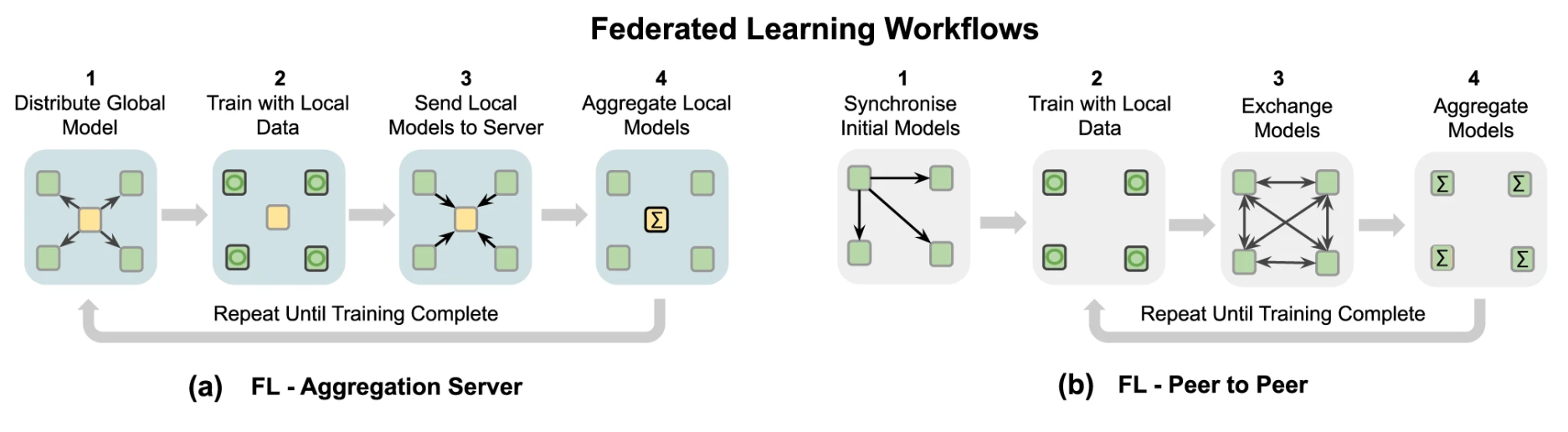
Federated Learning 意在解决分布式数据不能在机构间公开分享的训练场景。在训练时,各 Nodes 基于其拥有的数据更新模型(local update),随后这些模型数据被整合为 global model。与 Distributed Learning 的区别在于:Distr 将超大数据分散以加速训练,受限于通信的效率与信息完整(故而通常传输 Gradients);Fed 受限于数据隐私安全与数据的 non-IID 分布。
同态加密(Homomorphic Encryption)与差分隐私(Differential Privacy)是的常用手段。
* 同态加密
- 将原文加密后进行各种运算,其结果相当于在明文上运算后进行加密
- 当不信任中心节点时,可在训练节点对模型进行同态加密,在中心节点对加密模型进行整合,传输回训练节点后再进行解密
- 加法或乘法操作,但不能既做加法又做乘法;例如。RSA加密即同态乘法
* 差分隐私
- 当数据传输被监听时,在传输的模型中加入噪声,使得攻击者无法从模型的更新情况推断样本信息
- 会损失一些性能
已有一些 FL 框架:FLARE,PySyft,Flower...
模型整合
最基础的算法是 FedAvg(参考):对各节点模型参数的加权平均,权重是节点的样本数;FedSGD则是对Gradient的加权平均
{kind=link}
优化
个性化FL
FL协助获取初始模型/共享层,各节点基于此获得更好的个性化本地模型
-
FedPer:各节点模型由个性化层、基本层组成,加权整合基本层
-
Per-FedAvg:训练初始模型后,各节点在本地只需少数几轮训练就可以得到一个较好的本地模型(与MAML方法类似)
Tips
与其他ML任务一样,有时可以选择预训练的模型作为初始模型。除此之外,还可以在公共节点准备一个公用数据集,以减轻节点数据 non-IID 的情况。
当每个节点每一次返回数据的速度不同时,最慢的那一个将成为瓶颈。可以选择异步训练(ASGD),也可以多次本地更新后再整合模型(但 loss 可能随之增加)
在整合模型时,如果有些节点返回的模型与其余节点返回的模型差异过大,可以考虑降低它的权重;同理,连续两个时间点的模型如果差异过大,可能也不太对劲(应该是相对光滑的更新)
To Read
Auto-FedRL:https://arxiv.org/abs/2203.06338
Preventing Data Leakage:https://arxiv.org/abs/2208.10553
https://zhuanlan.zhihu.com/p/639999333:FedCE
https://zhuanlan.zhihu.com/p/560442664:FedSM
联邦学习中蒸馏技术为什么不流行?https://www.zhihu.com/question/587700297
Per-FedAvg 训练初始模型:https://zhuanlan.zhihu.com/p/539356815
FedOpt:https://zhuanlan.zhihu.com/p/660719221
联邦学习框架多方比较:https://zhuanlan.zhihu.com/p/411301846,https://zhuanlan.zhihu.com/p/540853969
Communication-efficient federated learning:https://www.pnas.org/doi/full/10.1073/pnas.2024789118?doi=10.1073%2Fpnas.2024789118,https://arxiv.org/abs/1808.07576